Synchronization
The programmer has specified which data is used by each of the
functions. Therefore, regardless of what happened prior to executing
this function, this data should be up-to-date on the active
device. The class-template Sync was designed to serve exactly
this purpose. Let's ignore the Dummy parameter, as it was
only necessary to specialize Sync within the scope of
Hybrid_ (one of the template peculiarities in
C++). Sync expects two template parameters which should
correspond to the parents of Hybrid_ (DefaultCPU
and DefaultGPU by default). The first argument corresponds to
the destination device, i.e. the device executing the current routine,
whereas the second argument is the device that currently has the
data. By default, noting happens when a Sync object is being
instantiated. It is however specialized for two other cases: CPU 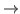 GPU, and GPU CPU.
GPU, and GPU CPU.
The implementation of Sync won't be listed here, but all it
does is call cudaMemcpy, where the direction
(e.g. cudaMemcpyHostToDevice) depends on the
specialization. An example of the implementation of one of the
routines however, is listed below:

Because the data-dependencies of multiplyM1() have been
specified as input, they are assumed to reside on the
CPU. Therefore, the Sync instantiation uses CPUType
as the source and MultiplyM1Device as its destination for
both vec1 and vec2. Here, MultiplyM1Device
is one of the typedef's from Hybrid_, using the
Get facility from the DevicePolicies parameter.
Joren Heit
2013-12-17